Saturday, 23 May 2020
Designing Cloud Native Apps in GCP
## Selecting the appropriate Cloud Service Model
- Infrastructure-as-a-service (IaaS) model
- large degree of fliexibility in implementation
- requries a significant amount of labor
- Software-as-a-service (SaaS) model
- higher velocity for delivery of services while maintaining a fair amount of flexibility
- at the expense of flexibility
- Iaas -> CaaS -> PaaS -> Faas -> Saas (from low fliexibility to high velocity)
## Protability and Design Consideration
- Protable Languages
- Platform considerations
- Platform specific designs are targeted for a specific environment
- Vendor lock in
## Evaluating Different Service Technologies
- Google App Engine
- you want to focus on writing code, never wants to touch a server, cluster or infrastructure
- you want to build a highly reliable and scalable serving app or component without doing it all yourself
- you value developer velocity over infrastructure control
- Minimize operational overhead
- Google Kubernetes Engine
- you want to increase velocity and improve operability dramatically by separating the app from the OS
- you need a secure, scalable way to manage containers in production
- you don't have dependencies on a specific operating system
- Google Compute Engine
- you need complete control over your infrastructure and direct access to high-performance hardware such as GPUs and local SSDs
- you need to make OS-level changes, such as providing your own network or graphic drivers, to squeeze out the last drop of performance
- You want to move your application from your own colo or datacenter to the cloud without rewriting it
- You need to run a software package that can't easily be containerized or your want to use existing VM images
## Operating System Considerations
- CentOS
- Container-optimized OS from Google
- CoreOS
- Debian
- Red Hat Enterprise Linux (RHEL)
- SUSE Enterprise Linux
- SLEX for SAP
- Ubuntu
- Windows Server
## Location of Your Service Components
- to cut down on latency and provide better services to your end users
## Microservice Architectures
- Separated into independent constituent parts, with each part having its own realm of responisbility
- Refactored from monolithic apps that have very tight coupling to a micro-service based architectures
- Advantages:
- the code base becomes more modular and easier to manage
- it becomes much easier to reuse services for other applications
- it is much easier to scale and tune individules services
## Defining Key Structures
- avoid monotonically increasing keys
- instead, migrate to keys that use random numbers, such as UUID
## Session Management
- keep a session cache
- Cloud Spanner
- a limit of 10K sessions per database per node
- a client can delete a session
- The Cloud Spanner database service can delete a session when the session is idle for more than 1 hour
## API Management Consideration
- Apps should be designed to have loosely coupled components
- Pub/Sub model enables event-driven architectures & asyn parallel processing
- Pulisher---(publish event)---> Event Channel --(Fire Event)---> Subscriber
- Pulisher---(publish event)---> Event Channel <--(Subscribe)---- Subscriber
## Health Checks
- Cloud Load Balancing
- Interal Load Balancing
- TCP Proxy Load Balancing
- SSL Proxy Load Balancing
- HTTP(s) Load Balancing
- Stackdriver Monitoring --- uptime check ---> storage/database/network
- Example:
```
gcloud compute health-checks create [PROTOCOl]
[HEALTH_CHECK_NAME] \
--description=[DESCRIPTION] \
--check-interval=[CHECK_INTERVAL] \
--timeout=[TIMEOUT] \
--healthy-threshold=[HEALTHY_THRESHOLD] \
--unhealthy-threshold=[UNHEALTHY_THRESHOLD] \
...additional flags
```
Thursday, 21 May 2020
Auto-upgrading nodes in GCP Containers
## Checking the state of auto-upgrade for an existing node pool
```
gcloud container node-pools describe node-pool-name \
--cluster cluster-name \
--zone compute-zone
```
## Enabling node auto-upgrades for an existing node pool
```
gcloud container node-pools update node-pool-name --cluster cluster-name \
--zone compute-zone --enable-autoupgrade
```
## Disabling node auto-upgrades for an existing node pool
where:
```
gcloud container node-pools update node-pool-name --cluster cluster-name \
--zone compute-zone --no-enable-autoupgrade
```
- node-pool-name is the name of the node pool.
- cluster-name is the name of the cluster that contains the node pool.
- compute-zone is the zone for the cluster.
Wednesday, 20 May 2020
Azure Synapse Analytics 101
- formerly Azure SQL Data Warehouse (SQL DW)
- Massively Parallel Processing (MPP) Data Warehouse
- Connection Security - Firewall rules are used by both the server and the database to reject connection attempts from IP addresses that haven't been explicitly whitelisted.
- Authentication - SQL pool currently supports SQL Server Authentication with a username and password, and with Azure Active Directory.
- Authorization - Authorization privileges are determined by role memberships and permissions. Authorization privileges are determined by role memberships and permissions.
- Data Encryption - protects against the threat of malicious activity by encrypting and decrypting your data at rest. Associated backups and transaction log files are encrypted without requiring any changes to your applications when encrypting your database.
- Advanced Data Security - provides a set of advanced SQL security capabilities, including data discovery & classification, vulnerability assessment, and Advanced Threat Protection.
## Transparent Data Encryption (TDE)
- It helps protect against the threat of malicious activity by encrypting and decrypting your data at rest. When you encrypt your database, associated backups and transaction log files are encrypted without requiring any changes to your applications. TDE encrypts the storage of an entire database by using a symmetric key called the database encryption key.
## Granular access controls
- Granular Permissions let you control which operations you can do on individual columns, tables, views, schemas, procedures, and other objects in the database. Use granular permissions to have the most control and grant the minimum permissions necessary.
- Database roles other than db_datareader and db_datawriter can be used to create more powerful application user accounts or less powerful management accounts. The built-in fixed database roles provide an easy way to grant permissions, but can result in granting more permissions than are necessary.
- Stored procedures can be used to limit the actions that can be taken on the database.
## Service Type
- Compute Optimized Gen1
- Compute Optimized Gen2
## Scalability
- Linear Scale on data warehouse unit
## Backup
- Use data warehouse snapshot to create a restore point
Monday, 18 May 2020
Deleting objects in GCP using Lifecycle Policy File
Example: Delete the object after 31 days.
```json
{
"rule":
[
{
"action": {"type": "Delete"},
"condition": {"age": 31}
}
]
}
```
Set the policy
```
gsutil lifecycle set life.json gs://$BUCKET_NAME_1
```
Get the policy
```
gsutil lifecycle get gs://$BUCKET_NAME_1
```
GCP Storage 101
- Use cases:
- website content
- storing data for archiving and disaster recovery
- distributing large data objects to users via direct download
- Scalable to exabytes
- Time to first byte in milliseconds
- Very high availability across all storage classes
- Single API across storage classes
## Signed URLs
- Valet key access to buckets and objects via ticket:
- crytographically signed URL
- time-limited
- operations specfied in ticket: HTTP, GET, PUT, DELETE (not POST)
- any user with URL can invoke permitted operations
- Example:
- ``gsutil signurl -d 10m path/to/privatekey.p12 gs://bucket/object``
## Strong Global Consistency
- read-after-write
- read-after-metadata-update
- read-after-delete
- bucket-listing
- object-listing
- granting access to resources
## Choose among Cloud Storage classes
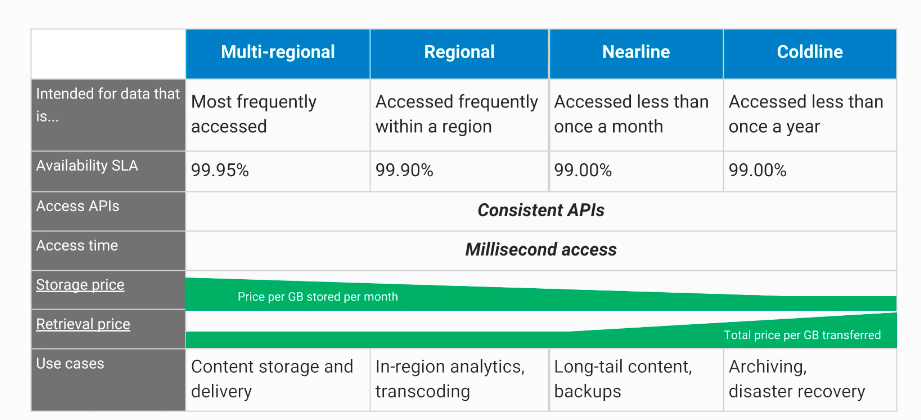
## Cloud Bigtable
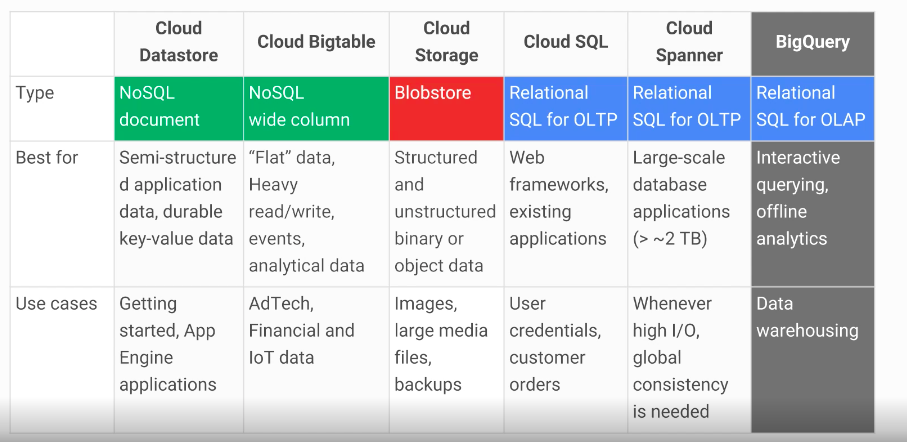
- Fully managed NoSQL, wide-column database service for terabyte applications
- Accessed using HBased API
- Native compatibility with big data Hadoop ecosystems
- Managed, scalable storage
- Data encryption in-flight and at rest
- Control access with IAM
- Bigtable drives major applications such as Google Analytics and Gmail
## Cloud SQL
- managed RDBMS
- offers MYSQL and PostgreSQLBeta databases as a service
- automatic replication
- managed backups
- vertical scaling (read & write)
- horizontal scaling (read)
- google security
- enable binary logging to use point-in-time recovery but it may slightly affect write performance
## Cloud Spanner
- horizontally scalable RDBMS
- strong global consistency
- managed instances with high availablity
- SQL queries
- ANSI 2011 with extensions
- automatic replication
## Cloud Datastore
- designed for application backends
- supports transactions
- includes a free daily quota
# Comparing Storage Options

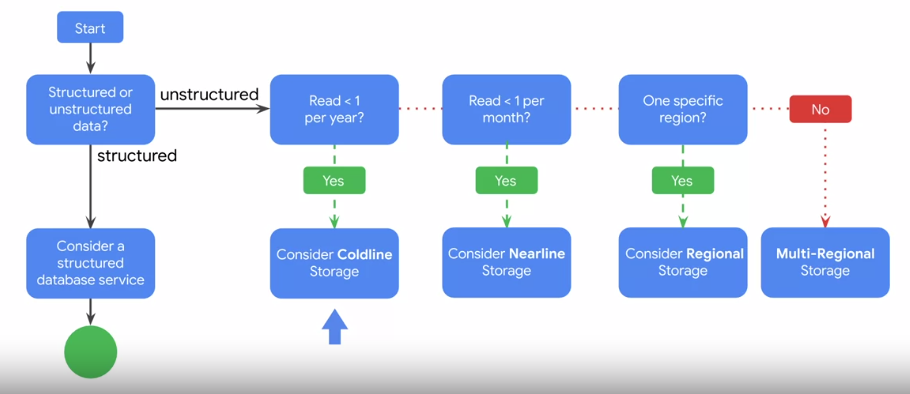
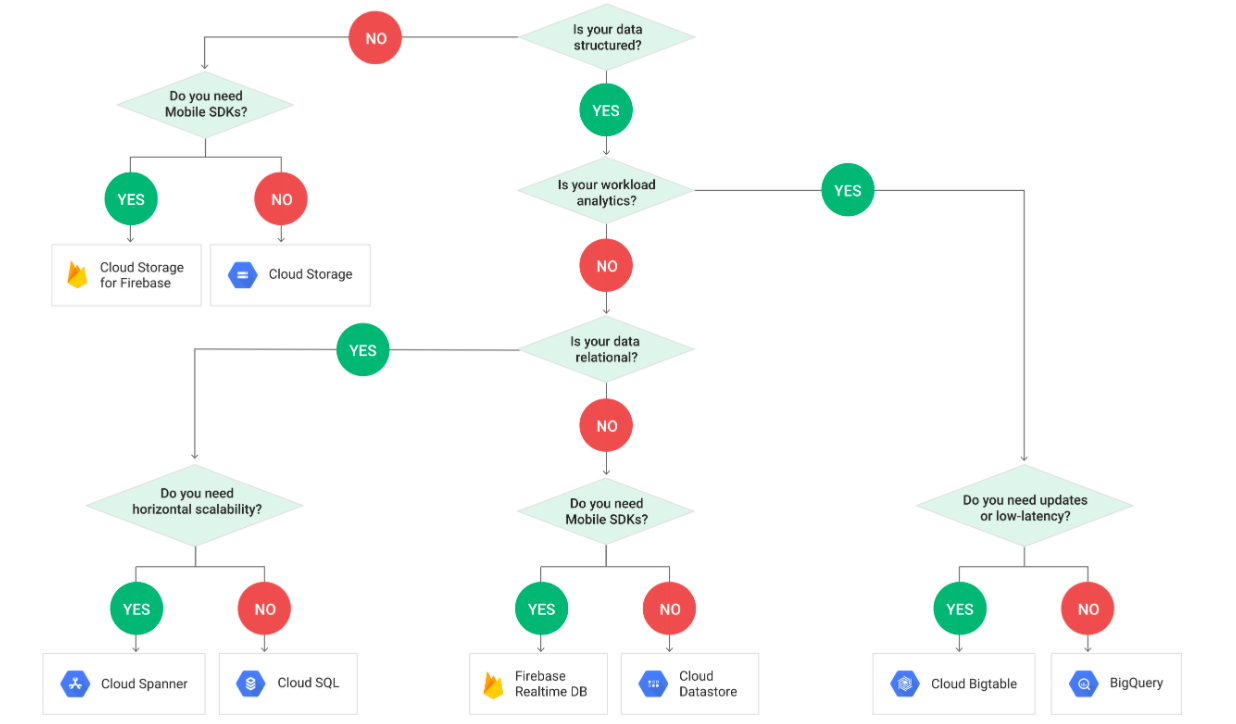
# Decision Flowchart
GCP SSH Keys 101
## Generating SSH Keys
```
ssh-keygen -t rsa -f ~/.ssh/[KEY_FILENAME] -C [USERNAME]
```
Restrict access
```
chmod 400 ~/.ssh/[KEY_FILENAME]
```
## Locating an SSH Key
```
Linux and macOS
Public key: $HOME/.ssh/google_compute_engine.pub
Private key: $HOME/.ssh/google_compute_engine
Windows:
Public key: C:\Users\[USERNAME]\.ssh\google_compute_engine.pub
Private key: C:\Users\[USERNAME]\.ssh\google_compute_engine
```
## Adding/Removing Project-Wide Public SSH Keys
```
gcloud compute project-info describe
```
```
...
metadata:
fingerprint: QCofVTHlggs=
items:
- key: ssh-keys
value: |-
[USERNAME_1]:ssh-rsa [EXISTING_KEY_VALUE_1] [USERNAME_1]
[USERNAME_2]:ssh-rsa [EXISTING_KEY_VALUE_2] [USERNAME_2]
...
```
Project Level
```
gcloud compute project-info add-metadata --metadata-from-file ssh-keys=[LIST_PATH]
```
Instance Level
```
gcloud compute instances add-metadata [INSTANCE_NAME] --metadata-from-file ssh-keys=[LIST_PATH]
```
## Blocking Project-Wide Public SSH Keys
```
gcloud compute instances add-metadata [INSTANCE_NAME] --metadata block-project-ssh-keys=TRUE
```
Creating a Health Check in GCP Compute
Create a health check
```
gcloud compute health-checks create http autohealer-check \
--check-interval 10 \
--timeout 5 \
--healthy-threshold 2 \
--unhealthy-threshold 3 \
--request-path "/health"
```
Create a firewall rule to allow health check probes to make HTTP requests
```
gcloud compute firewall-rules create default-allow-http-health-check \
--network default \
--allow tcp:80 \
--source-ranges 130.211.0.0/22,35.191.0.0/16
```
Pro Tip: Use separate health checks for load balancing and for autohealing. Health checks for load balancing detect unresponsive instances and direct traffic away from them. Health checks for autohealing detect and recreate failed instances, so they should be less aggressive than load balancing health checks. Using the same health check for these services would remove the distinction between unresponsive instances and failed instances, causing unnecessary latency and unavailability for your users.
Sunday, 10 May 2020
Getting Started with Kubernetes Engine
## Objectives
- Provision a Kubernetes cluster using Kubernetes Engine.
- Deploy and manage Docker containers using kubectl.
## Prerequisites
- Existing GCP Project
- Kubernetes Engine API and Google Container Registry API have been enabled
## Start a Kubernetes Engine cluster
In GCP console, on the top right toolbar, click the Open Cloud Shell button.
Click Continue.
Place the zone into an environment variable called MY_ZONE. At the Cloud Shell prompt, type this partial command:
```
export MY_ZONE=us-central1-a
```
Start a Kubernetes cluster managed by Kubernetes Engine. Name the cluster ``webfrontend`` and configure it to run ``2`` nodes:
```
gcloud container clusters create webfrontend --zone $MY_ZONE --num-nodes 2
```
It takes several minutes to create a cluster as Kubernetes Engine provisions virtual machines for you.
```
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
webfrontend us-central1-a 1.14.10-gke.27 35.223.99.22 n1-standard-1 1.14.10-gke.27 2 RUNNING
```
After the cluster is created, check your installed version of Kubernetes using the ``kubectl version`` command:
kubectl version
The ``gcloud container clusters create`` command automatically authenticated kubectl for you.
```
kubectl version
```
```
Client Version: version.Info{Major:"1", Minor:"14+", GitVersion:"v1.14.10-dispatcher", GitCommit:"f5757a1dee5a89cc5e29cd7159076648bf21a02b", GitTreeState:"clean", BuildDate:"2020-02
-06T03:29:33Z", GoVersion:"go1.12.12b4", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"14+", GitVersion:"v1.14.10-gke.27", GitCommit:"145f9e21a4515947d6fb10819e5a336aff1b6959", GitTreeState:"clean", BuildDate:"2020-02-21T
18:01:40Z", GoVersion:"go1.12.12b4", Compiler:"gc", Platform:"linux/amd64"}
```
View your running nodes in the GCP Console. On the Navigation menu (Navigation menu), click Compute Engine > VM Instances. Your Kubernetes cluster is now ready for use.

## Run and deploy a container
From your Cloud Shell prompt, launch a single instance of the nginx container. (Nginx is a popular web server.)
```
kubectl run nginx --image=nginx:1.10.0
```
In Kubernetes, all containers run in pods. This use of the kubectl run command caused Kubernetes to create a deployment consisting of a single pod containing the nginx container. A Kubernetes deployment keeps a given number of pods up and running even in the event of failures among the nodes on which they run. In this command, you launched the default number of pods, which is 1.
> Note: If you see any deprecation warning about future version you can simply ignore it for now and can proceed furthe
View the pod running the nginx container:
```
kubectl get pods
```
```
NAME READY STATUS RESTARTS AGE
nginx-fb9c7b94d-p7x4x 1/1 Running 0 2m32s
```
Expose the nginx container to the Internet:
```
kubectl expose deployment nginx --port 80 --type LoadBalancer
```
```
service/nginx exposed
```
Kubernetes created a service and an external load balancer with a public IP address attached to it. The IP address remains the same for the life of the service. Any network traffic to that public IP address is routed to pods behind the service: in this case, the nginx pod.
View the new service:
```
kubectl get services
```
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.51.240.1 443/TCP 5m42s
nginx LoadBalancer 10.51.242.185 80:31576/TCP 15s
```
You can use the displayed external IP address to test and contact the nginx container remotely.
It may take a few seconds before the External-IP field is populated for your service. This is normal. Just re-run the kubectl get services command every few seconds until the field is populated.
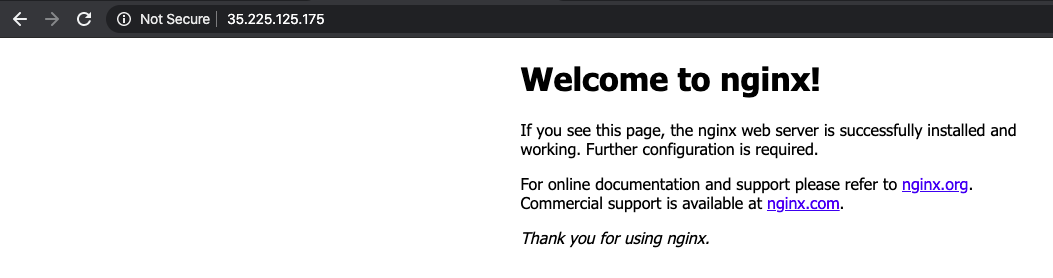
Open a new web browser tab and paste your cluster's external IP address into the address bar. The default home page of the Nginx browser is displayed.
Scale up the number of pods running on your service:
```
kubectl scale deployment nginx --replicas 3
```
```
deployment.extensions/nginx scaled
```
Scaling up a deployment is useful when you want to increase available resources for an application that is becoming more popular.
Confirm that Kubernetes has updated the number of pods:
```
kubectl get pods
```
```
NAME READY STATUS RESTARTS AGE
nginx-fb9c7b94d-p7x4x 1/1 Running 0 3m51s
nginx-fb9c7b94d-qvm4b 1/1 Running 0 18s
nginx-fb9c7b94d-sk4rm 1/1 Running 0 18s
```
Confirm that your external IP address has not changed:
```
kubectl get services
```
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.51.240.1 443/TCP 6m53s
nginx LoadBalancer 10.51.242.185 35.225.125.175 80:31576/TCP 86s
```
Return to the web browser tab in which you viewed your cluster's external IP address. Refresh the page to confirm that the nginx web server is still responding.
GCP Anthos 101
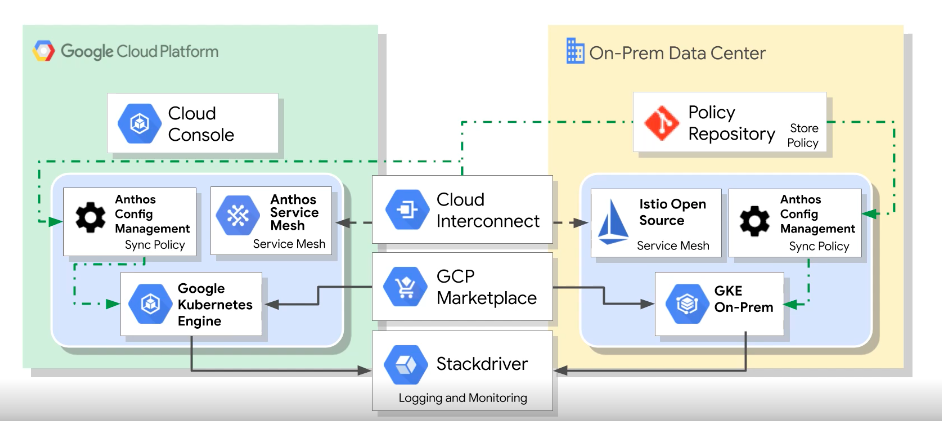
- google's modern solution for hybrid and multi-cloud systems and services management
- kubernetes and GKE on-prem create the foundation
- on-prem and cloud environments stay in sync
- a rich set of tools is provided for:
- manageing services on-prem and in the cloud
- monitoring systems and services
- migrating applications from VMs into your clusters
- maintaining consistent policies across all clusters, whether on-prem or in the cloud
Subscribe to:
Comments (Atom)