Sunday, 13 September 2020
Loading environment variables into Serverless
Storing config in the environment is one of the factors in The Twelve-Factor App. We do not want to store our environment variables in our code.
Normally the environment variables is stored in a file called ``.env`` in the root of the application and this file should be added to ``.gitignore`` so that no one can see the values. You may leave a file called ``.env.sample`` to let other team members to know what keys should be included.
Each line is composed in ``KEY=VALUE`` format. Blank lines and lines beginning with ``#`` are ignored.
Example:
```
AWS_REGION=ap-east-1
```
In order to load the environment variables so that the Lambda function can run successfully , we need to use ``serverless-dotenv-plugin`` to do so.
To install it, simply run
```
npm i -D serverless-dotenv-plugin
```
Then, add the following in your ``serverless.yml``
```
plugins:
- serverless-dotenv-plugin
```
Now you can include your environment variables in your serverless config by referencing them as ``${env:VAR_NAME}``.
```
region: ${env:AWS_REGION}
```
These variables are also injected into lambda functions so that you can reference them as ``process.env.SOMETHING``.
Friday, 4 September 2020
Streaming Data to Amazon S3 Using Kafka Connect S3
There is not a direct way to stream data to Amazon S3. You need a S3 Connector. The following demostration is performed in ``ap-east-1`` region and the Apache Kafka version is ``2.2.1``.
## Prerequisites
You should have
- MSK Cluster
- Client Machine
- Apache Kafka topic
- Producer
- S3 bucket
## Installation
Since we are not using Confluent Cloud, we need to download and install it manually.
Go to [https://www.confluent.io/hub/confluentinc/kafka-connect-s3](https://www.confluent.io/hub/confluentinc/kafka-connect-s3) to download Kafka Connect S3
Extract the ZIP file contents and copy the contents to the desired location. For example, you can create a directory named ``/home/ec2-user/kafka-plugins`` then copy the connector plugin contents.
## Configuration
Add this to the plugin path in your Connect properties file ``connect.properties``
```
plugin.path=/home/ec2-user/kafka-plugins/
```
Update ``bootstrap.servers``
```
bootstrap.servers=X-X.XXXXXXXXXXX-XX.XXXXXX.XX.kafka.ap-east-1.amazonaws.com:9092,X-X.XXXXXXXXXXX-XX.XXXXXX.XX.kafka.ap-east-1.amazonaws.com:9092
```
Update ``topic``
```
topic=<YOUR_KAFKA_TOPIC>
```
Define desired converter key and value. By default the value is empty, if you don't specify them, you will get ``JDBC Sink: JsonConverter with schemas.enable requires "schema" and "payload" fields and may not contain additional fields.`` error.
```
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.storage.StringConverter
value.converter.schemas.enable=false
```
If you want to convert the data to parquet format. You must use the AvroConverter with ParquetFormat. Attempting to use other Converter will result in a runtime exception.
```
key.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://10.0.0.0:8081
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://10.0.0.0:8081
```
Then, define sink connector properties. A sample properties file is available under ``etc/`` in the zip.
```
name=s3-sink
connector.class=io.confluent.connect.s3.S3SinkConnector
tasks.max=1
topics=<YOUR_KAFKA_TOPIC>
s3.region=ap-east-1
s3.bucket.name=<YOUR_BUCKET>
s3.part.size=5242880
flush.size=1
storage.class=io.confluent.connect.s3.storage.S3Storage
format.class=io.confluent.connect.s3.format.avro.AvroFormat
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
schema.compatibility=NONE
```
With ``flush.size`` > 1 and ``value.converter`` = ``JsonConverter`` , you may get ``org.apache.avro.AvroRuntimeException: already open`` error.
In order to contacting S3 successfully, you need to provide AWS credentials to authenticate for the S3 connector.
```
export AWS_ACCESS_KEY_ID=foo
export AWS_SECRET_ACCESS_KEY=bar
```
## Producing the data
Here's a sample producer
```py
from time import sleep
from json import dumps
from kafka import KafkaProducer
# Define Amazon MSK Brokers
brokers=['<YOUR_MSK_BROKER_1>:9092', '<YOUR_MSK_BROKER_2>:9092']
# Define Kafka topic to be produced to
kafka_topic='<YOUR_KAFKA_TOPIC>'
# A Kafka client that publishes records to the Kafka cluster
producer = KafkaProducer(bootstrap_servers=brokers, value_serializer=lambda x: dumps(x).encode('utf-8'))
# To produce 1000 numbers from 0 to 999
for num in range(1000):
data = {'number' : num}
producer.send(kafka_topic, value=data)
sleep(1)
```
Start to produce data to the topic
```
python3 ./producer.py
```
## Streaming data to S3
Run
```
~/kafka_2.13-2.6.0/bin/connect-standalone.sh ~/kafka-plugins/confluentinc-kafka-connect-s3-5.5.1/etc/connector.properties ~/kafka-plugins/confluentinc-kafka-connect-s3-5.5.1/etc/s3-sink.properties
```
## Result
You should see those objects with keys:
```
topics/<YOUR_KAFKA_TOPIC>/partition=0/<YOUR_KAFKA_TOPIC>+0+0000000000.avro
topics/<YOUR_KAFKA_TOPIC>/partition=0/<YOUR_KAFKA_TOPIC>+0+0000000001.avro
topics/<YOUR_KAFKA_TOPIC>/partition=0/<YOUR_KAFKA_TOPIC>+0+0000000002.avro
...
```
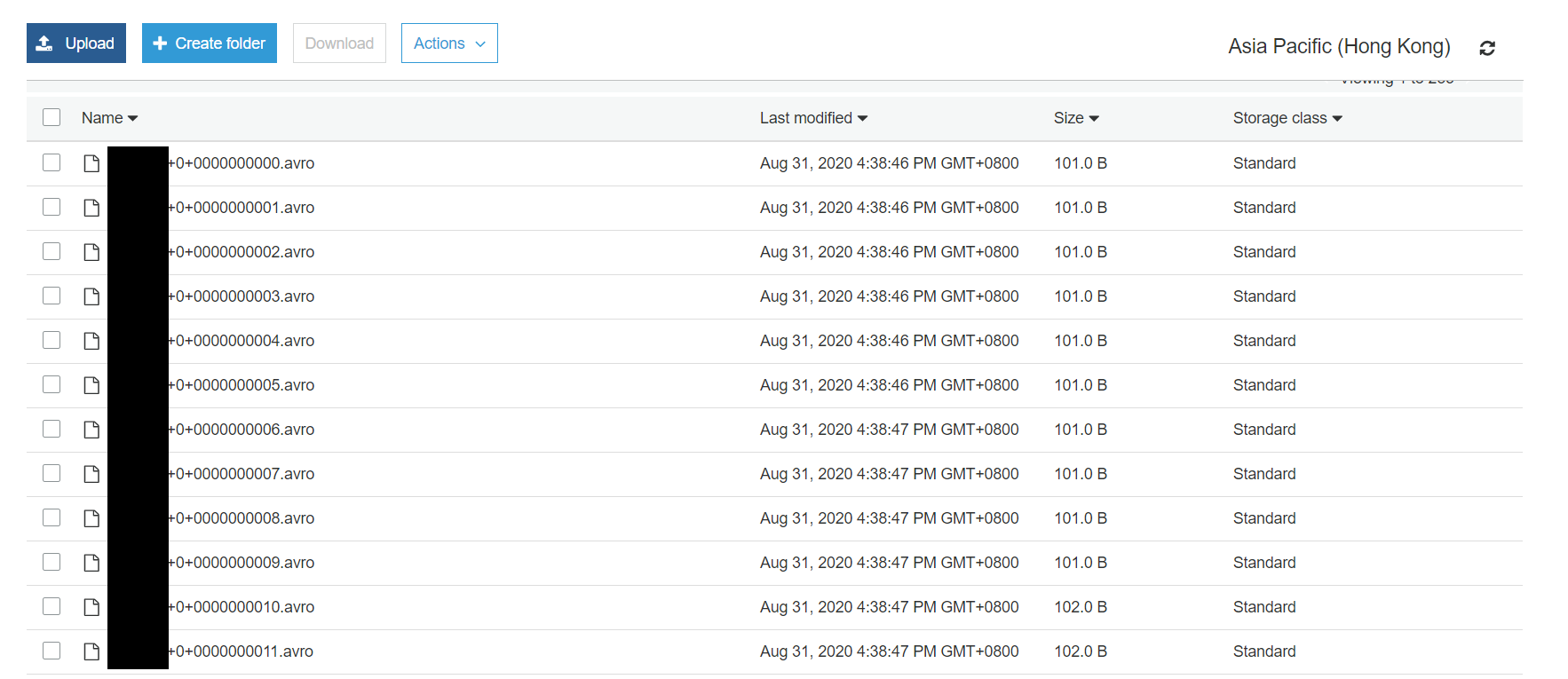
Download the first one verify. You can either use Avor Viewer to view it and export it as json
```json
[
{
"boolean": null,
"bytes": null,
"double": null,
"float": null,
"int": null,
"long": null,
"string": null,
"array": null,
"map": [
{
"key": {
"boolean": null,
"bytes": null,
"double": null,
"float": null,
"int": null,
"long": null,
"string": "number",
"array": null,
"map": null
},
"value": {
"boolean": null,
"bytes": null,
"double": null,
"float": null,
"int": null,
"long": 0,
"string": null,
"array": null,
"map": null
}
}
]
}
]
```
or use ``avro-tools-1.7.7.jar`` ([download here](http://mirror.metrocast.net/apache/avro/avro-1.7.7/java/avro-tools-1.7.7.jar)) to convert it back to json
```
java -jar avro-tools-1.7.7.jar tojson <YOUR_KAFKA_TOPIC>+0+0000000000.avro
```
```json
{"number":0}
```
If you want multiple records inside one .avro file, increase the value of ``flush.size``.
## Common issues
NoClassDefFoundError is thrown when using ``io.confluent.connect.s3.format.parquet.ParquetFormat ``
`` java.lang.NoClassDefFoundError: com/google/common/base/Preconditions``
Solution
Download the missing jar [guava-17.0.jar](https://www.findjar.com/jar/com/google/guava/guava/17.0/guava-17.0.jar.html) and add it back to ``/lib``
## Useful links
- [Amazon S3 Sink Connector for Confluent Platform](https://docs.confluent.io/current/connect/kafka-connect-s3/index.html)
- [Avor Viewer](https://zymeworks.github.io/avro-viewer/)
Getting started with Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Amazon MSK is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data.
## Create MSK Cluster
- [Via Console](https://docs.aws.amazon.com/msk/latest/developerguide/getting-started.html)
- [Via Amazon CDK](https://github.com/wingkwong/aws-playground/tree/master/msk/cdk)
## Create a Client Machine
- Create an EC2 instance to create a topic that produces and consumes data as you cannot access Amazon MSK directly from a local machine. The brokers and zookeeper connect string are private.
- Download [Apache Kafka](https://kafka.apache.org/downloads)
- Upload to ``~/`` and unzip it. Example: ``~/kafka_2.13-2.6.0/``
- Install ``python3`` by running ``sudo yum install -y python3``
- Install ``java`` by running ``sudo yum install java-1.8.0-openjdk``
- Install ``kafka-python`` by running ``sudo pip install kafka-python``
## Create Kafka Topic
Connect to the client machine
```bash
#!/bin/sh
zookeeperConnectString="<YOUR_ZOOKEEPER_CONNECT_STRING>" # retrieved from "View Client Information" in Amazon MSK Console
kafka_topic="<YOUR_KAFKA_TOPIC>"
replication_factor=1
partitions=1
# Change directory to Kafka bin
cd ~/kafka_2.13-2.6.0/bin/
# Execute kafka-topics.sh
./kafka-topics.sh --create --zookeeper $zookeeperConnectString --replication-factor $replication_factor --partitions $partitions --topic $kafka_topic
```
## Produce Data
```py
from time import sleep
from json import dumps
from kafka import KafkaProducer
# Define Amazon MSK Brokers
brokers=['<YOUR_MSK_BROKER_1>:9092', '<YOUR_MSK_BROKER_2>:9092']
# Define Kafka topic to be produced to
kafka_topic='<YOUR_KAFKA_TOPIC>'
# A Kafka client that publishes records to the Kafka cluster
producer = KafkaProducer(bootstrap_servers=brokers, value_serializer=lambda x: dumps(x).encode('utf-8'))
# To produce 1000 numbers from 0 to 999
for num in range(1000):
data = {'number' : num}
producer.send(kafka_topic, value=data)
sleep(1)
```
## Consume Data
```py
from kafka import KafkaConsumer
from json import loads
# Define Amazon MSK Brokers
brokers=['<YOUR_MSK_BROKER_1>:9092', '<YOUR_MSK_BROKER_2>:9092']
# Define Kafka topic to be consumed from
kafka_topic='<YOUR_KAFKA_TOPIC>'
# A Kafka client that consumes records from a Kafka cluster
consumer = KafkaConsumer(
kafka_topic,
bootstrap_servers=brokers,
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: loads(x.decode('utf-8')))
for message in consumer:
message = message.value
print('{}'.format(message))
```
## Common Issues
Thrown the following error while creating a Kafka topic
```
Exception in thread "main" kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING
at kafka.zookeeper.ZooKeeperClient.waitUntilConnected(ZooKeeperClient.scala:262)
at kafka.zookeeper.ZooKeeperClient.<init>(ZooKeeperClient.scala:119)
at kafka.zk.KafkaZkClient$.apply(KafkaZkClient.scala:1865)
at kafka.admin.TopicCommand$ZookeeperTopicService$.apply(TopicCommand.scala:360)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:55)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
```
Solution:
Check Securty Group to make sure that the inbound is allowed.
Wednesday, 2 September 2020
Building a CI/CD pipeline for a SAM application written in Go
This tutorial shows how to build a CI/CD Pipeline for a SAM Application written in Go with CodeCommit, CodeBuild, CodePipeline, CloudFormation and the AWS CDK.
## Prerequisites
You need to have an AWS account and installed and configured AWS CLI and Go.
## Initialize The Hello World SAM project
- Run ``sam init``
- Type 1 to select AWS Quick Start Templates
- Choose ``go1.x`` for runtime
- Leave default ``sam-app`` for project name
- Type 1 to select the Hello World Example
- Verify if ``sam-app`` have been created
When deploying this project, it will create an API Gateway, a Lambda function and a IAM Role. They are defined in ``template.yaml``.
```
HelloWorldAPI:
Description: "API Gateway endpoint URL for Prod environment for First Function"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"
HelloWorldFunction:
Description: "First Lambda Function ARN"
Value: !GetAtt HelloWorldFunction.Arn
HelloWorldFunctionIamRole:
Description: "Implicit IAM Role created for Hello World function"
Value: !GetAtt HelloWorldFunctionRole.Arn
```
The Lambda function simply prints out ``Hello World``.
```
func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) {
return events.APIGatewayProxyResponse{
Body: "Hello World!",
StatusCode: 200,
}, nil
}
```
## Run SAM Application Locally
SAM allows your to run your serverless application locally for your development and testing by running the following command. The default local port number is ``3000``. If you are running your app on Cloud9 workspace, you need to override it with ``--port`` as Cloud 9 only support 8080, 8081 or 8082 in the local browser.
```
sam local start-api --port 8080
```
You should see
```
Mounting HelloWorldFunction at http://127.0.0.1:8080/hello [GET]
You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template
* Running on http://127.0.0.1:8080/ (Press CTRL+C to quit)
```
Let's verify it
```
curl http://127.0.0.1:8080/hello
```
You should see
```
Hello World
```
## Deploy to AWS
Run ``sam build`` to build the project.
```
sam build
```
A hidden directory has been created by SAM
Run ``sam deploy`` to deploy your application. SAM will createa a CloudFormation stack and you can have a guided interactive mode by specifying ``--guided`` parameter.
```
sam deploy --guided
```
Configuring SAM deploy
```
Looking for samconfig.toml : Not found
Setting default arguments for 'sam deploy'
=========================================
Stack Name [sam-app]:
AWS Region [us-east-1]: ap-southeast-1
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [y/N]: y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: Y
HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: Y
Save arguments to samconfig.toml [Y/n]: Y
Looking for resources needed for deployment: Not found.
Creating the required resources...
Successfully created!
Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-542w25h26du5
A different default S3 bucket can be set in samconfig.toml
Saved arguments to config file
Running 'sam deploy' for future deployments will use the parameters saved above.
The above parameters can be changed by modifying samconfig.toml
Learn more about samconfig.toml syntax at
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html
Uploading to sam-app/9a42d6084bb2aaa2f7eaf7b2201e115a 5094701 / 5094701.0 (100.00%)
```
Deploying with following values
```
Stack name : sam-app
Region : ap-southeast-1
Confirm changeset : True
Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-542w25h26du5
Capabilities : ["CAPABILITY_IAM"]
Parameter overrides : {}
```
Initiating deployment
```
HelloWorldFunction may not have authorization defined.
Uploading to sam-app/21a49766581b625811536c904121d4ba.template 1154 / 1154.0 (100.00%)
Waiting for changeset to be created..
CloudFormation stack changeset
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Operation LogicalResourceId ResourceType
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
+ Add HelloWorldFunctionCatchAllPermissionProd AWS::Lambda::Permission
+ Add HelloWorldFunctionRole AWS::IAM::Role
+ Add HelloWorldFunction AWS::Lambda::Function
+ Add ServerlessRestApiDeployment47fc2d5f9d AWS::ApiGateway::Deployment
+ Add ServerlessRestApiProdStage AWS::ApiGateway::Stage
+ Add ServerlessRestApi AWS::ApiGateway::RestApi
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Changeset created successfully. arn:aws:cloudformation:ap-southeast-1:XXXXXXXXXXX:changeSet/samcli-deploy1598436540/ea868c52-9c9a-4d27-a008-ef6157f65b9b
```
Previewing CloudFormation changeset before deployment
```
Deploy this changeset? [y/N]: y
2020-08-26 18:09:42 - Waiting for stack create/update to complete
CloudFormation events from changeset
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ResourceStatus ResourceType LogicalResourceId ResourceStatusReason
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole -
CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole Resource creation Initiated
CREATE_COMPLETE AWS::IAM::Role HelloWorldFunctionRole -
CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction -
CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction Resource creation Initiated
CREATE_COMPLETE AWS::Lambda::Function HelloWorldFunction -
CREATE_IN_PROGRESS AWS::ApiGateway::RestApi ServerlessRestApi -
CREATE_IN_PROGRESS AWS::ApiGateway::RestApi ServerlessRestApi Resource creation Initiated
CREATE_COMPLETE AWS::ApiGateway::RestApi ServerlessRestApi -
CREATE_IN_PROGRESS AWS::Lambda::Permission HelloWorldFunctionCatchAllPermissionProd Resource creation Initiated
CREATE_IN_PROGRESS AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d -
CREATE_IN_PROGRESS AWS::Lambda::Permission HelloWorldFunctionCatchAllPermissionProd -
CREATE_IN_PROGRESS AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d Resource creation Initiated
CREATE_COMPLETE AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d -
CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdStage -
CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdStage Resource creation Initiated
CREATE_COMPLETE AWS::ApiGateway::Stage ServerlessRestApiProdStage -
CREATE_COMPLETE AWS::Lambda::Permission HelloWorldFunctionCatchAllPermissionProd -
CREATE_COMPLETE AWS::CloudFormation::Stack sam-app -
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
CloudFormation outputs from deployed stack
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Outputs
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Key HelloWorldFunctionIamRole
Description Implicit IAM Role created for Hello World function
Value arn:aws:iam::XXXXXXXXXXX:role/sam-app-HelloWorldFunctionRole-CXSDBGUHPMFS
Key HelloWorldAPI
Description API Gateway endpoint URL for Prod environment for First Function
Value https://yh1q5tcsqg.execute-api.ap-southeast-1.amazonaws.com/Prod/hello/
Key HelloWorldFunction
Description First Lambda Function ARN
Value arn:aws:lambda:ap-southeast-1:XXXXXXXXXXX:function:sam-app-HelloWorldFunction-13LO5HE0Y7BKS
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Successfully created/updated stack - sam-app in ap-southeast-1
```
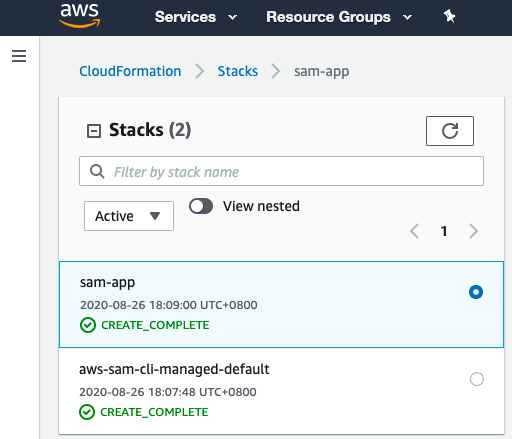
To verifiy it, click the HelloWorldApi Value in sam-app Output.
## Building the pipeline
With a continous delivery pipeline using AWS Code Pipeline, we can automate the build, package, and deploy commands. Other services will be used such as CodeCommit, CloudFormation and the AWS CDK.
The general flow would be like
```
Developer -- pushes changes --> Git Repository -- build --> deploy --> AWS
```
## Setting up CodeCommit
Let's create a CodeCommit repository
```
aws codecommit create-repository --repository-name sam-app
```
You should see the following output
```json
{
"repositoryMetadata": {
"accountId": "XXXXXXXXXXXX",
"repositoryId": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"repositoryName": "sam-app",
"lastModifiedDate": "2020-08-26T18:26:36.257000+08:00",
"creationDate": "2020-08-26T18:26:36.257000+08:00",
"cloneUrlHttp": "https://git-codecommit.ap-southeast-1.amazonaws.com/v1/repos/sam-app",
"cloneUrlSsh": "ssh://git-codecommit.ap-southeast-1.amazonaws.com/v1/repos/sam-app",
"Arn": "arn:aws:codecommit:ap-southeast-1:XXXXXXXXXXXX:sam-app"
}
}
```
To configurate git credentials
```
git config --global credential.helper '!aws codecommit credential-helper $@'
git config --global credential.UseHttpPath true
git config --global user.name "wingkwong"
git config --global user.email "wingkwong.code@gmail.com"
```
Go to the root directory of your SAM project and run
```
cd ./sam-app
git init
git add .
git commit -m "Initial commit"
```
Setup Git origin
```
git remote add origin
```
Push the code to origin
```
git push -u origin master
```
You should see
```
Counting objects: 17, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (13/13), done.
Writing objects: 100% (17/17), 4.86 MiB | 1.55 MiB/s, done.
Total 17 (delta 0), reused 0 (delta 0)
To https://git-codecommit.ap-southeast-1.amazonaws.com/v1/repos/sam-app
* [new branch] master -> master
Branch 'master' set up to track remote branch 'master' from 'origin'.
```
## Setting up CodePipline
We will use Amazon CDK to provision the pipeline.
### Install CDK
```
npm install -g aws-cdk
```
### Initialize the project
```
cdk init --language typescript
```
### To bulid and deploy
```
npm run build
cdk deploy
```
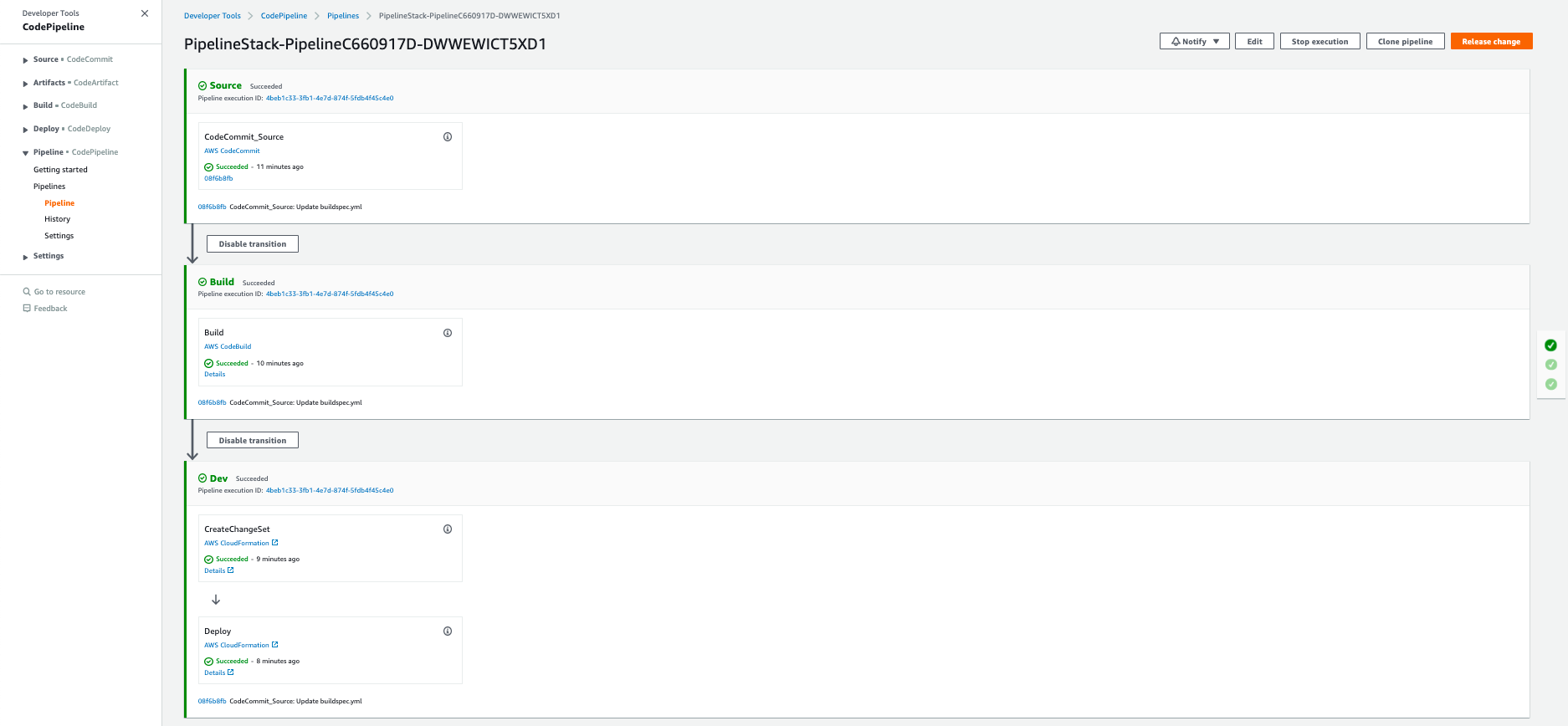
You should see ``PipelineStack`` has been created
Go to AWS Console -> Developer Tools -> CodePipeline -> Pipelines
## Clean up
```
cdk destroy PipelineStack
```
```
Are you sure you want to delete: PipelineStack (y/n)? y
PipelineStack: destroying...
11:21:26 PM | DELETE_IN_PROGRESS | AWS::CloudFormation::Stack | PipelineStack
11:22:34 PM | DELETE_IN_PROGRESS | AWS::IAM::Role | Pipeline/Dev/Creat...PipelineActionRole
11:22:34 PM | DELETE_IN_PROGRESS | AWS::IAM::Role | Pipeline/Build/Bui...PipelineActionRole
11:22:34 PM | DELETE_IN_PROGRESS | AWS::IAM::Role | Build/Role
✅ PipelineStack: destroyed
```
Subscribe to:
Posts (Atom)